
As we explored in Use Cases Where DPUs Shine the Kalray DPU is uniquely qualified for several data-intensive use cases. Kalray MPPA DPU architecture is differentiated to perform varying tasks with ease.
While many DPUs on the market rely on ARM cores – which aren’t any more suited to data processing or data protection than x86 cores – Kalray took the approach of having many cores which are very low power and specialize in instructions meant for data manipulation. No one will replace their x86 for general purpose application execution with these cores, and quite frankly, they shouldn’t.
Low Power, High Performance
Kalray cores shed all the “instruction set” baggage of an x86 or ARM processor. What’s left is a very low-power processor with just the right instruction set needed for all the workloads that you would expect a DPU to be good at. The result is more processing for less power.
Take the 80 cores found in a Kalray processor, cluster them so multiple processors can concurrently work on data sets residing in coherent shared memory and add a few hardware accelerators to the mix.
Then, go one step further and add coprocessors to each core that can offload complex math functions like vector and tensor math, and what do you get? A very low-power, cost-effective data processing unit that is adaptable to varying data sets, can use hardware assist to handle common tasks such as compression, encryption and KV (key value) hashing, and has the programmability to be effective in anyone’s data center.
All of this is fed by dual 100Gbe ethernet ports and x16 Gen 4 PCIe buses supporting both root complex and end point forms of communication.
Kalray’s MPPA® DPU Architecture: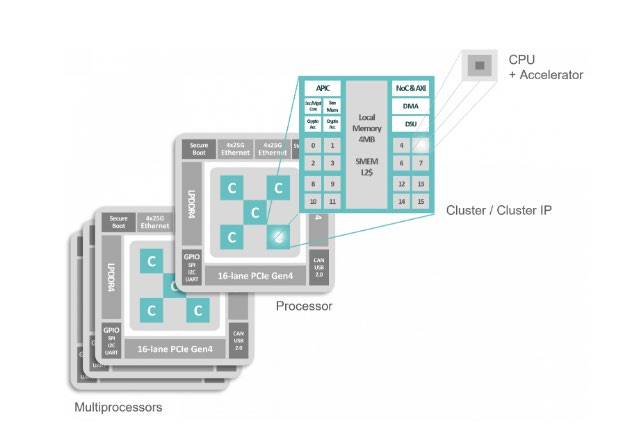
Hardware Optimized by Software
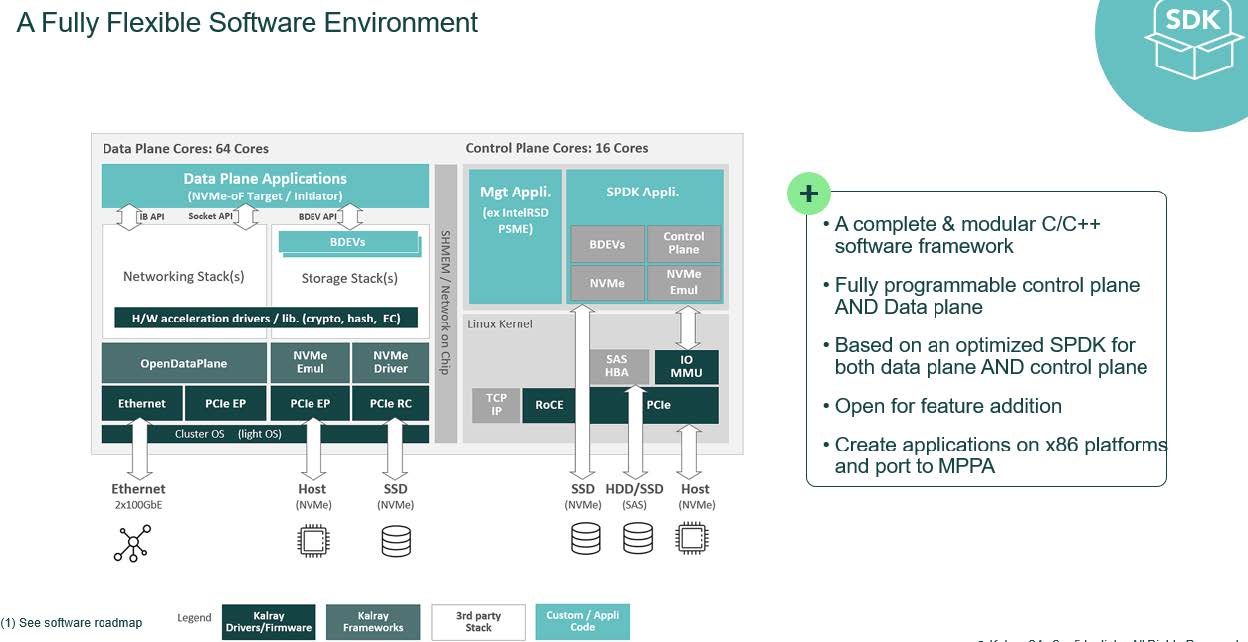
Kalray’s software stack is crucial because it provides the comprehensive and organized collection of components, frameworks, and tools need to make use of the MPPA’s functionality from simple device pass-through to modern data protection methods such as erasure coding.
The flexibility of the Kalray software stack allows for data center architectural changes such as resource disaggregation which we will discuss next.
The capacity and performance increase of modern NVMe SSDs has skyrocketed in the past several years such that servers can no longer take full advantage, basically stranding either capacity or performance resources.
Before NVMe SSDs, we talked about storage bottlenecks, now we talk about CPU bottlenecks. Disaggregation is a CPU bottleneck fix. When SSDs are removed from each individual server into disaggregated storage enclosures, each server can carve out the required resources it needs and leave the rest for other servers.
By disaggregating storage to fabric attached arrays, many servers can now take advantage of the SSDs that were isolated in a single server without loss of performance.
In this architecture no server shares its storage pool with other servers, or at least doesn’t have to if it doesn’t want to. The server’s x86 is not responsible for data management or services, since the storage is remote, so CPU resources are recovered through this mechanism as well.
In addition to pass-through, the Kalray DPU offers logical volumes to provide composable software-defined storage in whatever manner each application requires. This could mean defining what capacity, performance, availability, durability, or capacity efficiency is required of the storage.
With all this work happening in the storage array, the server is completely offloaded and available for additional billable work.
To make this possible, the software on the DPU completely manages the data plane and the control plane with programmable cores.
Most DPUs have one or both planes hardwired, as is the case for an ASIC, or have minimal flexibility in one or both planes because they rely on combinations of ASIC and ARM cores. The result in the Kalray DPU is a highly flexible architecture adaptable to any data center requirement.
The Card & The Chip
This DPU is highly programmable, and as such, offers the possibilities of either using standard offload features such as distributed data protection or distributed auto-tiering or developing function specific customer applications, such as computational storage-like functions which could offload database queries.
The Kalray software stack is divided between a data plane and control plane allowing both to be programmed independently from each other, both planes utilize open-source software such as SPDK and DPDK, which allows developers to write/debug code on an x86 and port to the Kalray DPU.
With this combination of standard offload and high degree of programmability, there’s no reason for a CPU or GPU to participate in data management.
Remember the mantra – let each processor (CPU, DPU and GPU) do what it’s best at.[Link to CPU/GPU/DPU Blog] It has been a point of discussion, if not of action, to develop technology to move compute to the data.
There is simply too much data in a modern data center to adhere to the old paradigm where data is moved to each compute complex which needs to perform some analysis.
The result is too many copies of the data, the possibility of incoherent data sets and poor use of fabric bandwidth. How much east-west fabric bandwidth is consumed moving copies of data to where there’s resources to consume it? And how much precious time is lost in those moves?
Data Acceleration: Bringing Processing Closer to the Data
Imagine an architecture where there are bunches of DPUs located at the data source (in each JBOF). These DPUs have already performed their primary duty by storing the data with some QoS-defined metrics around performance, durability, and availability.
They have also performed their duty of reducing the data for maximum efficiency of the allocated capacity, saving power and dollars by replacing x86 based servers with DPU-based JBOFs.
So now the DPUs are ready to take on data analytics. Instead of passing large datasets over the fabric to CPUs and GPUs, they can take on the function of data analysis locally and simply pass the results back to the requesting server or GPU farm for subsequent analysis or decision. Or they can perform meta-data creation while the data is at rest.
The DPUs are data set aware and pre-analyze the data for either a final result (which the x86 can use for decision making) or to reduce the data set to a manageable subset for deeper analysis by the CPU or GPU.
Unlock Acceleration – and Savings – for Your Company
It doesn’t take much imagination to understand the savings in latency, in fabric bandwidth and in servers (x86 or GPU). Even if the savings are on the order of just 10 to 15%, that means 15% less servers in the data center or fabric savings which could be the tipping point to push out the next technology jump. Want to make your CIO happy? Tell them that your data center won’t be spending capital on a new fabric upgrade for a couple of years.
But first, let’s talk. Book a Meeting